

ℨ𝔢𝔯𝔬 (っ◔◡◔)っ @[email protected]
- zer0zero-mstd [at] yahoo [dot] com
- PGP
- A551 B8F6 A13D 8A90 (long key ID)
- Pronouns
- 他 / he / him
Dh'oine.
Va'esse deireádh aep eigean, va'esse eigh faidh'ar.
横幅图片为好奇号火星车 2022 年 2 月在火星上拍到的一块像花一样的石头. Credit: NASA, JPL-Caltech, MSSS
我不使用屏蔽其他人的功能;我不使用隐藏其他实例的功能;我不会隐藏一个我正在关注的人.
加入于 2020年10月
ℨ𝔢𝔯𝔬 (っ◔◡◔)っ
转嘟

Building a Functional LEGO Typewriter
https://youtube.com/watch?v=ZIWTSkCVxjk
ℨ𝔢𝔯𝔬 (っ◔◡◔)っ
转嘟

读过 鳗鱼的旅行 🌕🌕🌑🌑🌑
被书名骗了……还以为是科普,实际是反正不是科普的什么书,乱七八糟的,更适合发表在网络上作为博客,不适合出版成书。值得一读的章节:第一章、第七章、第十五章,第十七章。
ℨ𝔢𝔯𝔬 (っ◔◡◔)っ
转嘟

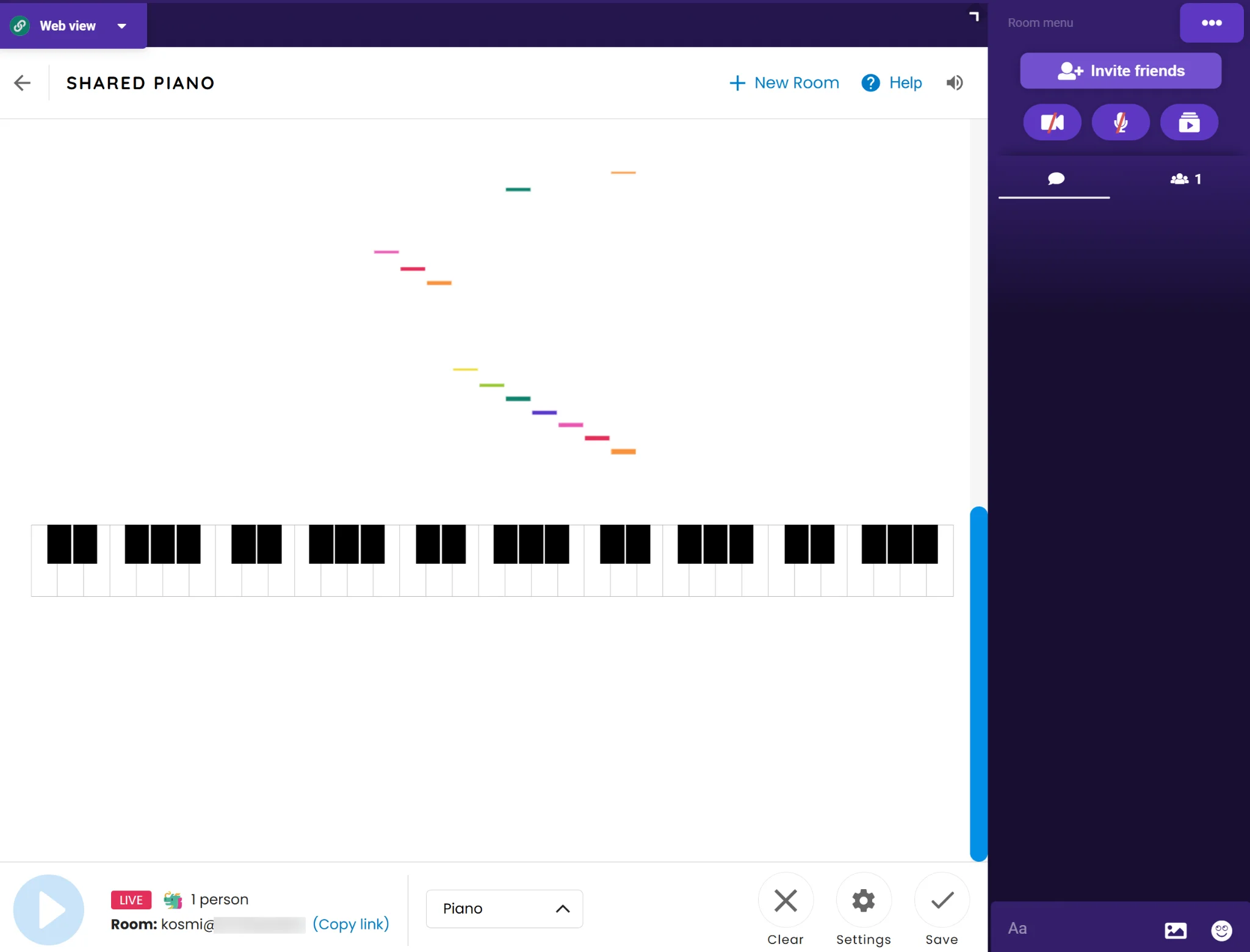
分享一个可以在线聚会的网站Kosmi
https://app.kosmi.io
Kosmi - Online Hangouts Made Easy
可以建房间,能语音视频,能一起浏览网页、看流媒体,支持播放本地视频,还自带了一些小游戏和程序比如MS画图、弹琴。
之前有嘟友喊人一起看柯南电影还费老劲装插件来着,有这个就方便多了
#软件安利
https://app.kosmi.io
Kosmi - Online Hangouts Made Easy
可以建房间,能语音视频,能一起浏览网页、看流媒体,支持播放本地视频,还自带了一些小游戏和程序比如MS画图、弹琴。
之前有嘟友喊人一起看柯南电影还费老劲装插件来着,有这个就方便多了
#软件安利
ℨ𝔢𝔯𝔬 (っ◔◡◔)っ
转嘟
看过 小艾米丽 🌕🌕🌕🌕🌕
人没有两岁前的记忆;孩子的以自我为中心;对危险的迟钝;对万事都有自己的理解;大人无法理解我们的感受(关于鲤鱼)。烹饪与战争。
ℨ𝔢𝔯𝔬 (っ◔◡◔)っ
转嘟

原文: 为什么有人说在现代计算机体系中链表已死
这个问题很有意思,我在招聘面试的时候,经常拿这个问题来筛选候选人。
我发现一个现象,刚毕业两三年的同学,往往会背诵教科书上的答案,告诉我链表在插入删除上是 O(1),数组是 O(N),所以链表灵活。工作了五年以上的资深工程师,尤其是做过高性能网关或者存储引擎的,听到链表这两个字,眉头会先皱一下,然后告诉我:能不用就别用。
现在是2026年,计算机硬件架构的发展,其实一直在强化一个趋势,那就是计算比访存快太多了。
链表已死这种说法,虽然听起来激进,但它指出了现代软件工程中一个极为核心的矛盾,那就是抽象的数据结构理论与真实的硬件物理特性之间的脱节。
我们在学校学数据结构时,老师会画一个个圆圈代表节点,用箭头代表指针,告诉我们这叫逻辑结构。在那个纯逻辑的世界里,访问内存的代价被假设为常数,是均等的。但现实世界里,内存访问不仅不是均等的,甚至有着天壤之别。
我们先得把账算清楚。
在现代 CPU 看来,从 L1 缓存拿数据就像是从自己办公桌上拿文件,耗时大约是 3 到 4 个时钟周期。从 L2 拿稍微远点,大概十几个周期。从 L3 拿可能要四五十个周期。但是,如果你从主内存(RAM)里拿数据,那就像是让你去隔壁城市的档案馆调档案,耗时是几百个时钟周期。
这几百个时钟周期里,CPU 是无事可做的,流水线会停顿,这就是著名的冯·诺依曼瓶颈,或者叫内存墙。
链表最大的原罪,恰恰就在这里。
标准的链表节点在内存里是离散分布的。你申请一个节点,它可能在内存地址 0x1000,下一个节点可能就在 0x8000。当你遍历链表时,CPU 必须先读取当前节点的 next 指针,拿到下一个地址,然后才能发起下一次内存读取请求。这是一个串行的、依赖性极强的过程。
CPU 里那个极度聪明的硬件单元,叫预取器,面对链表时几乎是束手无策的。预取器最擅长的是线性模式,它看到你在读地址 x,又读了 x+1,它就会极其兴奋地把 x+2、x+3 乃至后面的一大块内存都提前拉到缓存里等着你。
所以当你遍历数组或者 std::vector 时,你以为你在遍历内存,其实你大部分时间是在遍历 L1 缓存,那个速度是极快的。而当你遍历链表时,你是在实打实地撞墙。每一次指针跳转,大概率都是一次缓存未命中(Cache Miss)。
现在的 CPU 主频动不动就 4GHz、5GHz,核心数越来越多,算力过剩。但内存延迟这么多年了,并没有本质的数量级提升。DDR5 甚至 DDR6 主要是带宽大了,延迟其实没降多少。这就导致了一个结果:谁能更好地利用缓存,谁就能赢。
很多教科书上说链表插入是 O(1),这在数学上没错,但在工程上是个巨大的误导。
为了完成这个 O(1) 的插入,你首先得遍历到插入点。如果你没有持有插入点的指针,你得从头遍历,那还是 O(N)。就算你持有了指针,仅仅为了这一个节点的插入操作,你可能需要经历一次 malloc 内存分配。内存分配器本身的开销、锁竞争、以及分配出来的新节点极其可能导致的缓存冷启动,这些隐形开销加在一起,往往比直接在数组里 memmove 挪动数据的开销还要大。
我曾经在一个高频交易系统的重构项目中做过测试。在数据量小于几千甚至上万个元素这个级别,std::vector 的插入删除性能完全吊打 std::list。只有当元素大到一定程度,或者拷贝构造函数的代价极高时,链表的理论优势才会体现出来。但在现代 C++ 里,我们有了右值引用和移动语义,对象的移动成本大大降低了,这进一步压缩了链表在业务逻辑层的生存空间。
所以,在应用层开发,也就是我们平时写的业务逻辑代码里,我倾向于认为标准的双向链表确实是半截身子入土了。Java 里的 LinkedList 几乎没人用,C++ 里的 std::list 也是被嫌弃的对象。如果你现在的业务代码里到处都是散乱的链表,那大概率是性能优化的低垂果实。
但这就意味着链表彻底死了吗?
这正是我要说的第二层逻辑。链表并没有死,它只是下沉了,或者说它进化了。它从一个通用的业务容器,退化(或者说升级)成了一种系统级的构建原语。
我们来看看链表在哪些地方依然是不可替代的。
首先是侵入式链表。
这是很多资深 C/C++ 工程师的看家本领,也是 Linux 内核能够高效运转的基石。在标准库的链表中,节点包裹着数据,数据是节点的一部分。但在侵入式链表中,链表节点(那个 next/prev 指针结构)是数据结构里的一个成员变量。
这种设计极其巧妙。它不需要显式地去 malloc 一个节点容器,因为节点本身就嵌在你的业务对象里。当你把一个对象加入链表时,没有任何内存分配发生,仅仅是几个指针的赋值操作。这意味着完全没有内存碎片,也没有分配器的开销。
在 Linux 内核里,这种 list_head 结构无处不在。进程调度队列、驱动设备列表、文件系统缓存,全都是靠这种侵入式链表串起来的。在这种场景下,链表不仅没死,反而是唯一的选择。因为这里的对象生命周期极其复杂,它们可能同时存在于多个链表中(比如一个网络包既在接收队列里,又在处理队列里),用数组根本没法表达这种多重归属关系。
其次是无锁编程和并发数据结构。
这是链表最后的堡垒。当我们在多线程环境下操作共享数据时,数组的劣势就暴露无遗。你想在数组中间插入一个元素,你需要移动后面的所有元素。这个移动过程不是原子的,要想保证线程安全,你必须加一把大锁,锁住整个数组。在高并发场景下,这把锁就是性能的噩梦。
而链表呢?链表的节点操作是局部的。我要在 A 和 B 之间插入 C,我只需要修改 A 的 next 指针和 C 的指针。利用现代 CPU 提供的 CAS(Compare-And-Swap)原子指令,我们可以极其优雅地完成这个操作,而不需要锁住整个链表。
著名的 Michael-Scott 队列,以及各种无锁栈、无锁哈希表,底层逻辑几乎全是基于链表节点的原子操作。在这里,链表的指针解耦特性成为了实现高并发的救命稻草。数组因为内存布局过于紧密,牵一发而动全身,反而成了累赘。
再往深了看,内存分配器本身就是链表的忠实拥趸。
不管是 glibc 的 malloc,还是 Google 的 tcmalloc,或者是 Facebook 的 jemalloc,它们在管理空闲内存块时,用的都是空闲链表(Free List)。当你释放一块内存,分配器把它标记为空闲,并把它串到一个链表上。下次你要申请同样大小的内存时,它直接从链表头摘下来给你。
这里用链表是因为,这块内存本来就是空闲的,我不利用它自己的空间来存指针,难道还要专门开辟个数组来记账吗?这种原地利用空闲内存存储链表指针的技巧,是底层系统的基本操作。
所以你看,链表在宏观的业务数据容器层面上,确实是被数组和哈希表打败了。因为在那个层面上,缓存局部性和内存带宽是王道。但在微观的系统控制层面上,在那些需要极致的灵活性、需要管理离散生命周期、需要高并发原子操作的地方,链表依然是王者。
还有一个很有意思的视角,叫做面向数据设计(Data-Oriented Design, DOD)。
这个概念在游戏开发领域非常火,现在也慢慢渗透到后端架构中。DOD 的核心思想就是:不要把数据组织成对象,要组织成流。
在传统的面向对象编程(OOP)里,我们有一个 Player 类,里面有位置、血量、装备。如果我们有一万个玩家,我们就有个链表串起一万个 Player 对象。当你遍历更新逻辑时,CPU 就得满内存乱跳,一会儿读位置,一会儿读血量,这是典型的对硬件不友好。
DOD 提倡的是 Structure of Arrays (SoA)。我搞一个大数组只存位置,另一个大数组只存血量。当我更新物理位置时,我只遍历位置数组。这时候 CPU 的预取器开心坏了,SIMD 指令集也能用上了,性能直接起飞。
在这种设计哲学下,链表是被严厉打击的对象。现在的游戏引擎,像 Unity 的 ECS(Entity Component System)架构,或者 Unreal 的一些底层模块,都在拼命地去除链表,把数据压平,压进连续的内存块里。因为在每秒 60 帧的硬指标面前,缓存未命中的代价是无法承受的。
甚至在这一波 AI 浪潮里,大模型的推理和训练,归根结底是矩阵运算。矩阵是什么?就是极其规整的二维数组。GPU 的设计初衷就是为了并行吞吐这种连续数据。你给 CUDA 核心塞一个链表试试?它处理分支跳转的能力非常弱,处理链表这种指针追逐逻辑,效率会低到让你怀疑人生。
所以从算力演进的大方向看,硬件确实在惩罚非连续内存访问。
不过,技术是有轮回的。
最近我也注意到一些新的编程语言,比如 Rust 和 Zig,它们在重新教育开发者如何使用内存。
Rust 的借用检查器(Borrow Checker)其实让写链表变得非常痛苦。你在 Rust 里写一个双向链表,简直是在跟编译器搏斗。这其实是一个很强的暗示:别乱用指针,别乱搞复杂的图结构,除非你真的需要。
于是我们看到了一种复古的潮流:用数组模拟链表。
也就是所谓的索引池(Index Pool)或者代际索引(Generational Index)。原理很简单,我申请一大块连续的数组内存作为对象池,然后我不存指针了,我存数组下标(Index)。我的 next 字段存的不是 0x8000 这样的内存地址,而是 123 这样的整数下标。
这样做的好处简直是两头通吃:
第一,数据都在大数组里,内存是相对连续的,对缓存友好。
第二,通过下标访问,依然保留了链表的 O(1) 插入删除特性(只要标记 slot 为空闲即可)。
第三,下标是整数,比 64 位的指针更省空间(如果数组没那么大的话,用 32 位整数就够了),进一步压缩了带宽压力。
这种带索引的数组链表,正在成为高性能系统的新宠。它本质上是承认了“物理上我们喜欢数组”,但“逻辑上我们需要链表”。这是一种极其务实的妥协。
还有一点不得不提,就是图(Graph)和树(Tree)。
有人说链表死了,那二叉树死没死?图死没死?它们本质上就是多叉链表。如果链表死了,那数据库的索引 B+ 树怎么办?
其实数据库领域早就给出了答案。B+ 树之所以能成为数据库索引的事实标准,而不是红黑树或者 AVL 树,根本原因就是B+ 树是“矮胖”的。一个节点不是存一个数据,而是存一页(Page)的数据,比如 4KB 甚至 16KB。
这本质上是什么?这就是链表和数组的混合体。宏观上,页面之间通过指针(或者逻辑页号)链接,这是链表。微观上,页面内部是有序数组。
这种设计就是为了适配磁盘 IO 和内存缓存的块大小。每次加载一个节点,正好填满缓存行或者磁盘块。如果用普通的二叉链表,读一个节点只用到了几十个字节,剩下的几千字节 IO 带宽都浪费了。
所以,即使是树结构,也在努力让自己变得“像数组一样连续”。
回到最初的问题。链表真的被淘汰了吗?
如果你指是那个 struct Node { T data; Node* next; } 的朴素链表,在应用层的大部分场景下,它确实应该被淘汰。如果在 2026 年写 C++ 代码,你还在无脑用 std::list 存这存那,那代码 Review 的时候肯定会被我打回去。
但如果你指的是通过引用/指针/索引来构建数据之间的逻辑拓扑关系,那它永远不会死。因为世界本身不是线性的。社交网络是图,组织架构是树,多对多关系网是网。只要我们需要表达非线性的关系,我们就需要“链接”。
只不过,资深的工程师懂得如何把这种逻辑上的链接,映射到物理上连续的内存中去。
我们会用数组去模拟树(堆排序),用 CSR(压缩稀疏行)去存储图,用 RingBuffer 去替代链式队列。我们不再天真地认为 malloc 出来的节点会乖乖地排好队等 CPU 来读。
这就是为什么我说,链表已死是一个很好的警钟。它提醒我们,不要被抽象蒙蔽了双眼。
写代码的时候,脑子里要有一张计算机体系结构的图。你要看得到数据在内存总线上流动的样子,要听得到 CPU 预取器工作的声音。 (1/2)
ℨ𝔢𝔯𝔬 (っ◔◡◔)っ
转嘟

ℨ𝔢𝔯𝔬 (っ◔◡◔)っ
转嘟

今天人生第一次在结冰的湖面上行走,还有幸看到姑娘在冰面上花滑诶! 今天柳暗花明,转角看到壮丽的山谷时和Emma对望,几乎同时说,这不是lofoten的山吗,我们为啥要去挪威来着🤣

ℨ𝔢𝔯𝔬 (っ◔◡◔)っ
转嘟
#知乎日报 既然人的体温为 37℃,那为什么在 35℃ 的气温下,人们觉得很热而不是凉快? https://daily.zhihu.com/story/9787056
- zer0zero-mstd [at] yahoo [dot] com
- PGP
- A551 B8F6 A13D 8A90 (long key ID)
- Pronouns
- 他 / he / him
Dh'oine.
Va'esse deireádh aep eigean, va'esse eigh faidh'ar.
横幅图片为好奇号火星车 2022 年 2 月在火星上拍到的一块像花一样的石头. Credit: NASA, JPL-Caltech, MSSS
我不使用屏蔽其他人的功能;我不使用隐藏其他实例的功能;我不会隐藏一个我正在关注的人.
加入于 2020年10月
ℨ𝔢𝔯𝔬 (っ◔◡◔)っ 的推荐:




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
